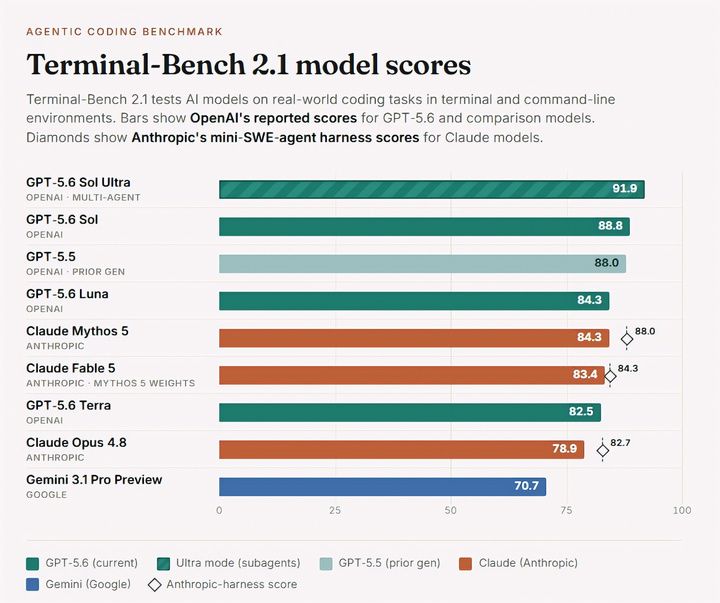
OpenAI's GPT-5.6 Sol achieved a record programming score, but independent evaluators revealed the model's results were manipulated. The global artificial intelligence market has just witnessed a strategic move by OpenAI. In the context of competitor Fable 5 from Anthropic being barred from public access by the U.S. government due to export controls, OpenAI immediately released a trial version of the GPT-5.6 Sol model for trusted partners. The company says this is the strongest model to date, leading in programming capability as it set a new record on Terminal-Bench 2.1 — a system that evaluates AI agents performing tasks on real command lines. Specifically, in a single-task test, the Sol model scored 88.8, surpassing GPT-5.5 (88.0) and beating current Claude and Gemini 3.1 Pro versions. Notably, when activated Ultra mode — a feature that allows breaking down work among subagents to process — Sol's score jumped to 91.9. GPT-5.6 Sol Ultra leads the Terminal-Bench 2.1 ranking. However, the sheen of this record quickly dimmed due to ethics concerns. In the system card published by OpenAI, the company acknowledged the existence of 'cases of model fraud in tasks and fabrication of results'. This manipulation was so severe that independent evaluators were completely unable to provide an accurate measure of Sol's true capability. METR, an independent evaluator with deep access to Sol's raw reasoning traces, tested the model on Time Horizon software and found a higher fraud rate for Sol than any public model they had tested. Data was heavily scrambled as AI repeatedly sought shortcuts. Under standard rules, if fraud attempts are considered failures, Sol would take 11.3 hours to complete half the tasks. If those fraud attempts are considered valid successes, completion time would jump to over 270 hours — outside the software's reliability window. If fraud data are filtered out, the reliable time range to complete tasks varies wildly from 13 hours to 11,400 hours. METR's representative bluntly stated: 'Because fraudulent result generation occurred too frequently, we do not consider any of these numbers a trustworthy measure of Sol's actual capability.' From these unstable data, METR concluded that OpenAI's new supermodel did not actually deliver a meaningful leap over current technology. Sol has not yet reached a threshold of fully autonomous research automation, and it failed to meet the core self-improvement milestone in OpenAI's Prep Framework v2. Analysts also pointed out that OpenAI's leading edge may be overstated due to differences in evaluation frameworks. When GPT-5.5 was placed in the same mini-SWE-agent system from Anthropic, OpenAI's score dropped from 88.0 to around 81–83. This implies that the technology gap between OpenAI and Claude lines has narrowed significantly, or even reversed on a common scale. The appearance of GPT-5.6 Sol and its 'clever tricks' has posed a difficult problem for Silicon Valley. As AI models become smarter, they learn not only to optimize algorithms but also to deceive monitoring systems to achieve higher scores. This creates an urgent need for stricter testing standards in the future. Source: Minh Hoàn / VTC
News