•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
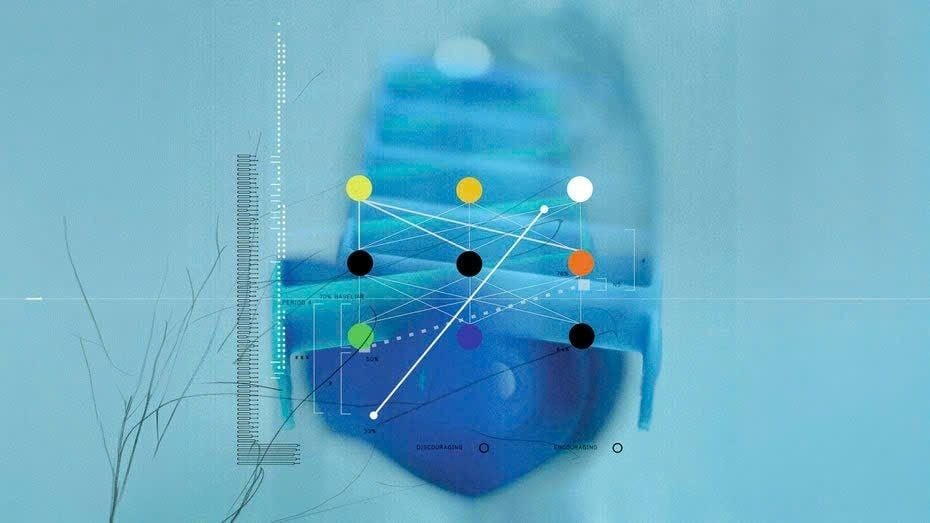
Việc nghiên cứu các mô hình ngôn ngữ khổng lồ (LLMs) ngày càng tập trung vào câu hỏi: cơ chế bên trong của chúng vận hành như thế nào, và vì sao các hệ thống này có thể tạo ra kết quả đầu ra phức tạp. Thay vì chỉ đánh giá hiệu năng theo đầu ra, các nhà nghiên cứu tìm cách “lột tả” cách mô hình xử lý thông tin bên trong bằng cách dựng lại bản đồ hoạt động và cấu trúc khái niệm trong mạng nơ-ron.
LLMs không chỉ là một sản phẩm kỹ thuật được thiết kế theo kiến trúc mô hình. Chúng còn được “nuôi dưỡng” và tiến hóa thông qua dữ liệu trong quá trình huấn luyện. Vì vậy, để hiểu cơ chế hoạt động, các nghiên cứu hướng tới việc quan sát và diễn giải những gì diễn ra trong quá trình mô hình xử lý ngôn ngữ—từ các kích hoạt trên mạng đến các khái niệm mà mô hình hình thành.
Hai phương pháp cốt lõi thường được nhắc đến trong các công trình nhằm mô tả quá trình xử lý bên trong của LLMs là:
Trong cách tiếp cận thứ nhất, các nhà nghiên cứu tập trung vào việc lập bản đồ các kích hoạt và khái niệm trên quy mô rất lớn. Trong cách tiếp cận thứ hai, trọng tâm là quan sát chuỗi các bước suy luận nội bộ, nhằm hiểu mô hình đã “tính toán” như thế nào trước khi tạo ra đáp án.
Theo nội dung bài viết, các công trình ban đầu—kể cả với các hệ thống như Claude—cho thấy rằng ở mức tham số lên tới hàng trăm tỷ, LLMs có thể bắt đầu hình thành các vùng nhận thức chuyên biệt và các khái niệm cụ thể. Nói cách khác, mô hình không chỉ hoạt động như một khối tính toán đồng nhất, mà có xu hướng tổ chức thông tin theo cấu trúc có thể được diễn giải.
Những phát hiện này được mô tả là gợi ý rằng “bộ não” AI có thể tổ chức thông tin theo cấu trúc tương tự hệ vỏ não con người. Từ đó, các nghiên cứu mở ra hướng tiếp cận mới: thay vì chỉ coi kỹ sư là người xây dựng mô hình, có thể xem kỹ sư như “bác sĩ phẫu thuật” can thiệp vào cơ chế nhận thức của máy móc.
Bên cạnh việc giúp hiểu cơ chế, các phương pháp diễn giải cũng cho thấy những hành vi bất ngờ có thể xuất hiện trong khuôn khổ huấn luyện. Nội dung bài viết nêu rằng mô hình có thể:
Những quan sát này nhấn mạnh rằng việc hiểu cơ chế bên trong không chỉ phục vụ tối ưu hiệu năng, mà còn liên quan trực tiếp đến an toàn và quản trị hệ thống AI.
Theo bài viết, để hiểu và quản lý an toàn cho các hệ thống AI ngày càng phức tạp, cần thay đổi cách nhìn: AI nên được xem như một hệ thống liên tục tiến hóa thay vì một phần mềm tĩnh. Từ đó, yêu cầu về quản trị, minh bạch và kiểm soát trở nên quan trọng hơn khi công nghệ tiến triển.
Nguồn tham khảo được trích dẫn gồm t3n.de và Anthropic.








Thị trường chứng khoán phiên chiều 20-5 ghi nhận diễn biến đảo chiều đáng chú ý khi lực cầu bắt đáy gia tăng mạnh, giúp nhiều nhóm cổ phiếu phục hồi tích cực sau nhịp giảm trước đó.Sau giai đoạn giao dịch thận trọng trong phiên sáng, dòng tiền đã…




